[ ] 分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化平方误差。也就是被预测出错的样本越多,错的越离谱,平方误差就越大,通过最小化平方误差能够找到最可靠的分枝依据.
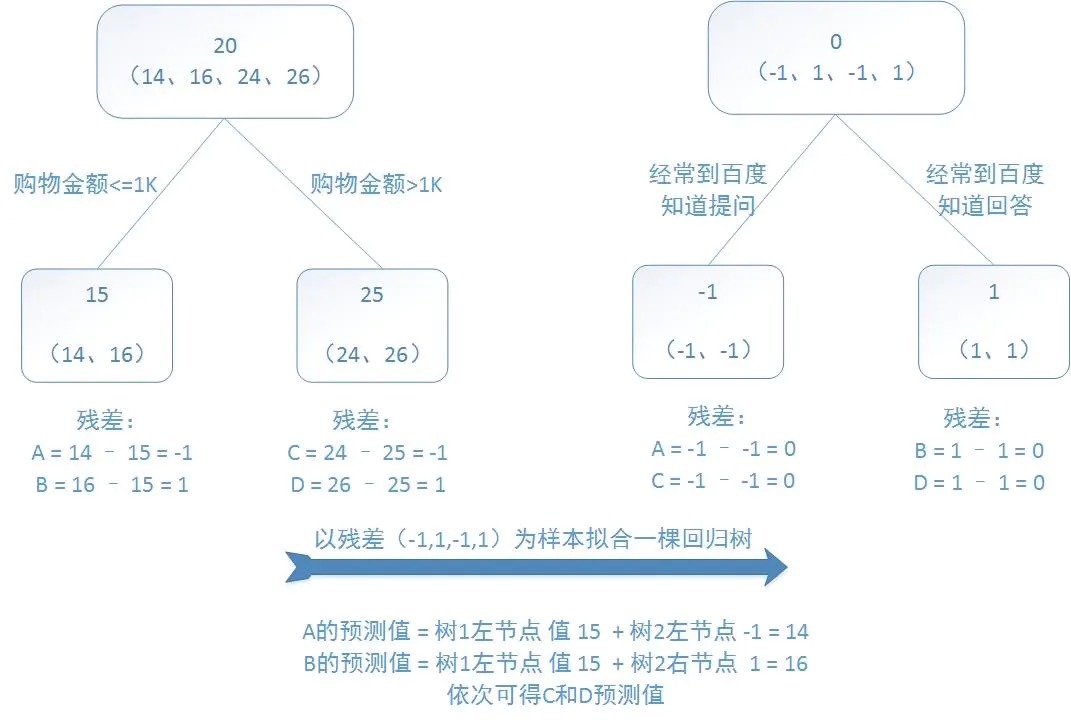
[ ] 提升树算法,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树,残差的意义如公式:残差 = 真实值 - 预测值 。提升树即是整个迭代过程生成的回归树的累加。
[ ] GBDT 算法的核心是利用损失函数的负梯度在当前模型的值作为算法中的残差近似值,算法思想是不断拟合残差,从而使残差不断减少,GBDT 算法每次 迭代构造的 CART 树都是用前一次迭代的残差拟合的。则第 m 次迭代第 i 个样本 的损失函数的负梯度值为:
[ ]

[ ] GBDT分类算法和GBDT回归算法,根本不同是损失函数选择的不同.GBDT回归算法选择平方差损失函数,GBDT分类算法则选择对数函数作为算是函数.
[ ] AdaBoost是根据样本的权重而调整训练的,而 GBDT 是根据残差的调整而进行训练的。通过对梯度迭代和决策树算法的有效结合,使得GBDT算法最终得到的分类器模型具有非常好的泛化能力以及极高的准确率。