
[TOC]
不久前微软DMTK(分布式机器学习工具包)团队在GitHub上开源了性能超越其他boosting工具的LightGBM,在三天之内GitHub上被star了1000次,fork了200次。知乎上有近千人关注“如何看待微软开源的LightGBM?”问题,被评价为“速度惊人”,“非常有启发”,“支持分布式”,“代码清晰易懂”,“占用内存小”等。
LightGBM (Light Gradient Boosting Machine)(请点击https://github.com/Microsoft/LightGBM)是一个实现GBDT算法的框架,支持高效率的并行训练。
LightGBM在Higgs数据集上LightGBM比XGBoost快将近10倍,内存占用率大约为XGBoost的1/6,并且准确率也有提升。GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。
LightGBM提出的主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数(其实又是分桶的思想,而这些桶称为bin,比如[0,0.1)→0, [0.1,0.3)→1),同时构造一个宽度为k的直方图。
在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
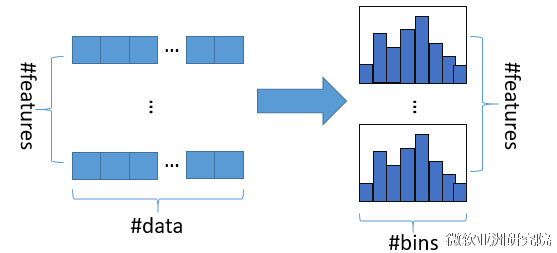
使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data*#feature)优化到O(k*#features)。