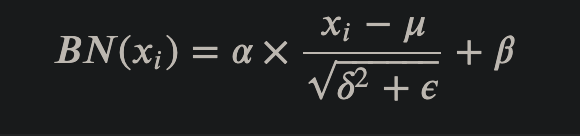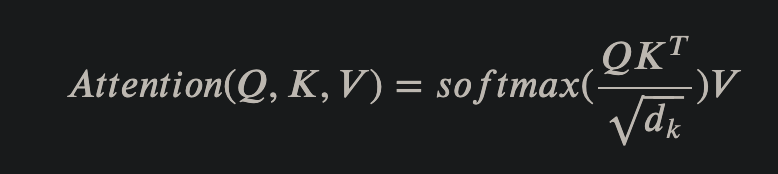输入层包括Word Embedding和Positional Encoding。Word Embedding可以认为是预训练的词向量,Positional Encoding用于捕获词语的相对位置信息。
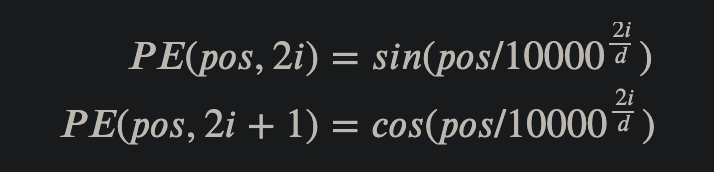
[TOC]
ransformer由论文《Attention is All You Need》提出,现在是谷歌云TPU推荐的参考模型。论文相关的Tensorflow的代码可以从GitHub获取,其作为Tensor2Tensor包的一部分。哈佛的NLP团队也实现了一个基于PyTorch的版本,并注释该论文。

- transformer由Encoder和Decoder组成,都包含6个block.Transformer的工作流程:
-
1. 获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据通过word2Vec等方法提取出来的Feature) 和单词位置的 Embedding 相加得到。
-

-
1. 将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用 表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
-
1. 将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
- 每一个Encoder的输入是下一层Encoder输出,最底层Encoder的输入是原始的输入(法语句子);Decoder也是类似,但是最后一层Encoder的输出会输入给每一个Decoder层,这是Attention机制的要求。
- 每一层的Encoder都是相同的结构.他由一个self-Attention层和一个前馈网络组成.
-

- 每一层的Decoder也是相同的结构,它除了Self-Attention层和全连接层之外还多了一个普通的Attention层,这个Attention层使得Decoder在解码时会考虑最后一层Encoder所有时刻的输出。
-

2.3 使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)


输入层包括Word Embedding和Positional Encoding。Word Embedding可以认为是预训练的词向量,Positional Encoding用于捕获词语的相对位置信息。
层标准化将数据标准化为均值为0,标准差为1.
缩放点积(Scaled dot-product Attention)是Self-Attention的基础,因此这里先实现它。该模块输入是K,Q,V三个张量,输出Context上下文张量和Attention张量
论文中使用了8个head,也就是把上述的K,Q,V三个张量按照维度分为8份,每份都经过仿射变换后送入到缩放点积中。 主要流程为:将K,Q,V进行仿射变换,得到对应的query,key和value;然后将它们根据head数目进行维度划分,送入到对应的缩放点积模块进行训练,得到Context张量和Attention张量;多个head的Context张量拼接后经过线性变换就得到了全局的Context张量;最后为了使模型能够更深,收敛更快,对输出加上了dropout,残差连接和层标准化。