勒索病毒和木马网络行为分析与识别技术探究
一、引言
互联网技术飞速发展,恶意代码的威胁也与日俱增。像僵尸网络、勒索软件这类恶意代码,借助网络通信达成其恶意目的,给网络安全带来了巨大挑战。传统的检测方法,如基于主机行为和静态特征的检测,已经难以应对恶意代码不断变化的情况。因此,本文提出了一种基于网络流量特征的检测方法,为恶意代码的识别提供了新的思路。
二、核心技术特征
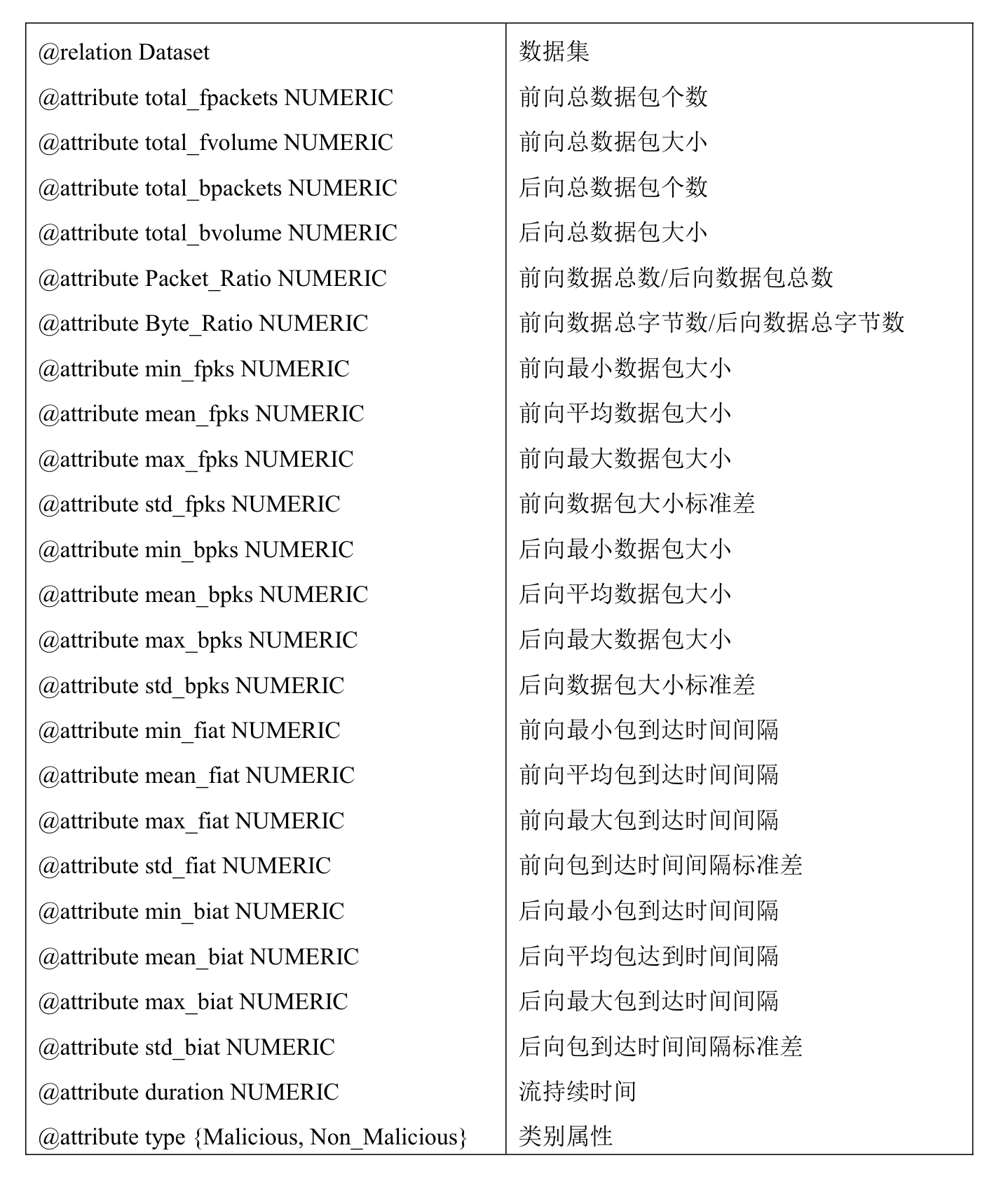
(一)网络流特征集
- 时间相关特征
- 流持续时间:指网络流从开始到结束的时间差。恶意代码的网络流持续时间通常较短且集中,比如Zeus僵尸网络的流持续时间大多在特定区间内,而正常网络流量的持续时间则较为分散。
- 数据包到达时间间隔:包括前向和后向数据包的最大、最小、平均时间间隔以及标准差。恶意代码如Gh0st木马会周期性发送心跳包,其数据包到达时间间隔的标准差较小,平均值也较为固定。
- 数据统计特征
- 数据包大小:涵盖前向和后向数据包的最大、最小、平均大小以及标准差。恶意代码产生的数据包大小分布相对集中,例如Zeus僵尸网络的数据包大小分布就比较固定,而正常网络访问的数据包大小分布则较为分散。
- 前后向数据量比率:包括前向数据包总数与后向数据包总数的比率,以及前向数据总字节数与后向数据总字节数的比率。恶意代码的网络流量上下行比例往往呈现出一定的模式,如Zeus僵尸网络的部分网络流前向数据量是后向数据量的十倍左右。
- 基本行为特征
(二)特征工程优势
三、检测原理与流程
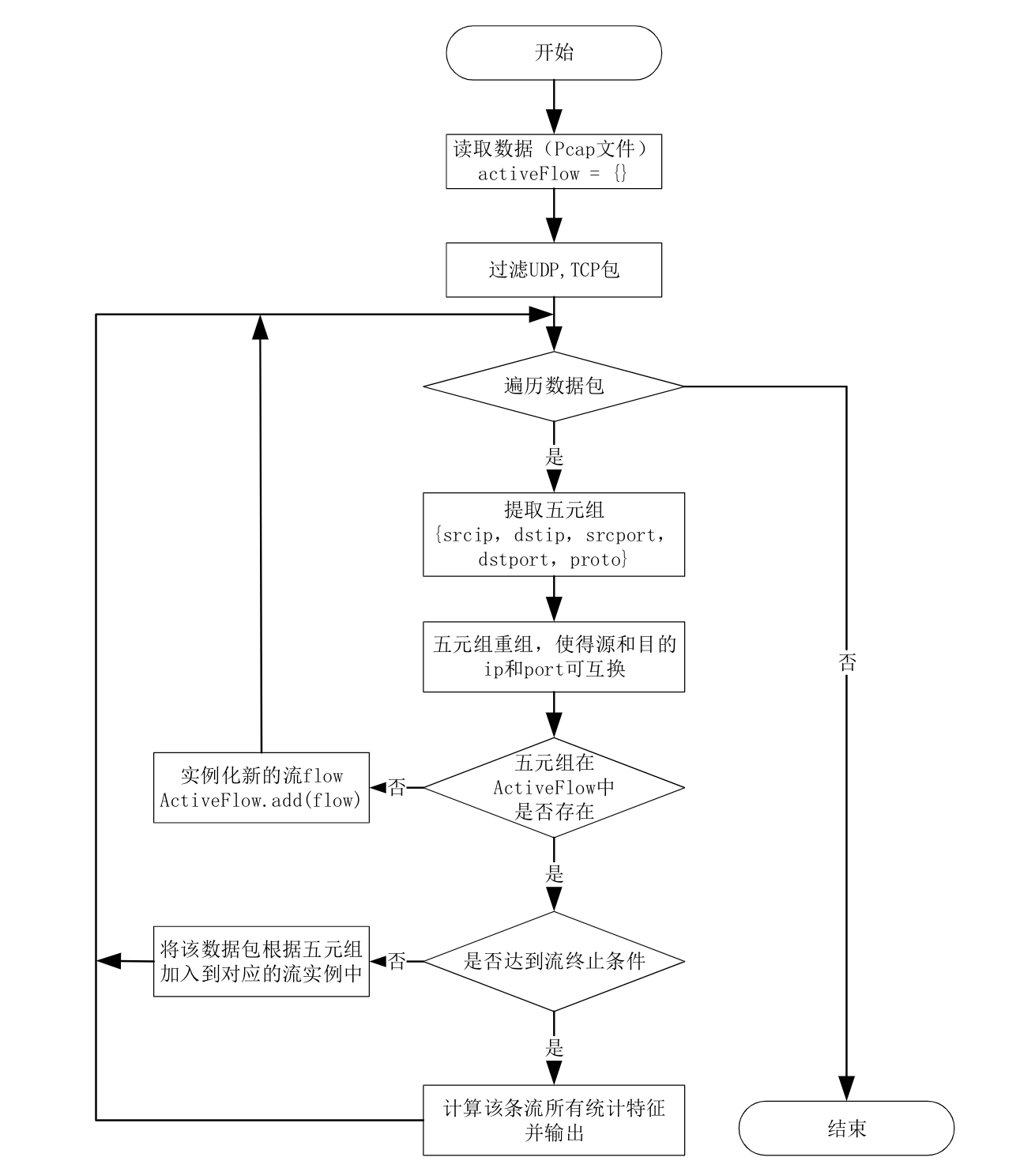
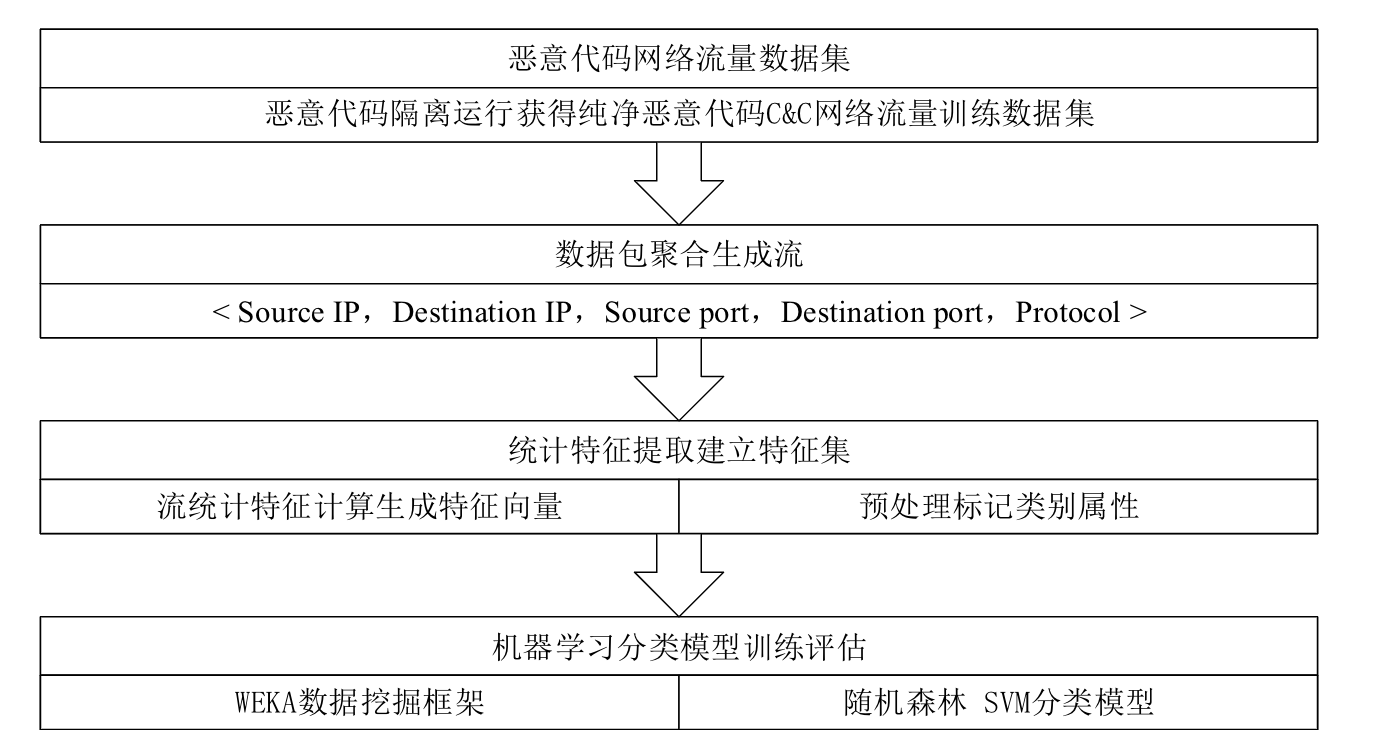
(一)基于五元组的数据包聚合
将网络数据包按照五元组(源IP、源端口、目标IP、目标端口、协议)进行聚合,形成网络流。TCP流根据FIN、RST报文和超时来判断结束,UDP流则以时间超时作为结束条件。这样可以将双向的数据包整合在一起,更好地反映网络通信的整体情况。
(二)随机森林分类模型
- 算法原理
随机森林是一种集成学习方法,它通过自助法重采样技术生成多个决策树,每个决策树在训练时随机选择部分特征和样本。最终的分类结果由多个决策树投票决定,从而提高了模型的准确性和鲁棒性。
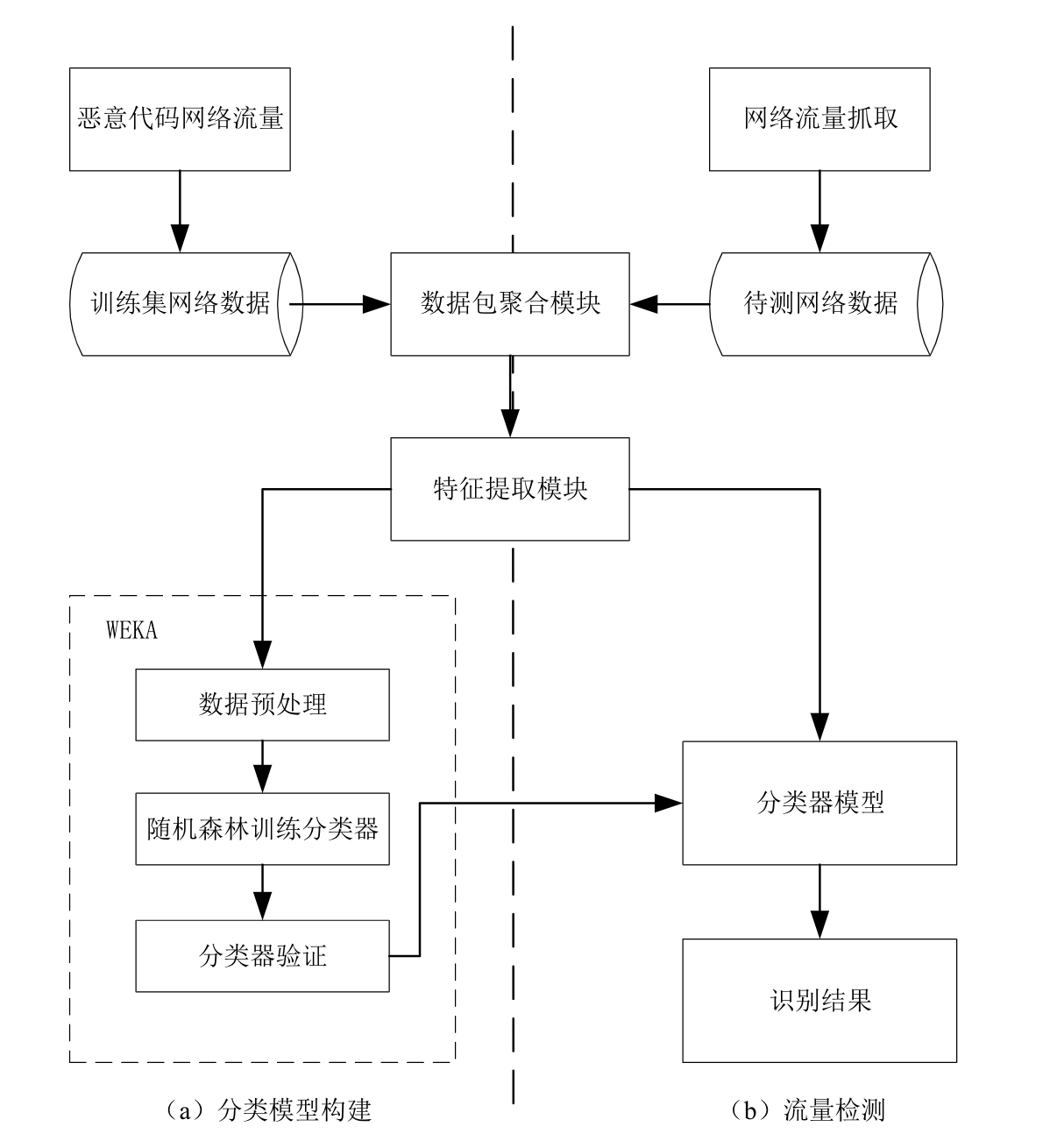
- 分类流程
-
数据预处理:将抓取的网络流量数据转换为WEKA所需的ARFF文件格式,并标记类别属性。
-
模型训练:使用训练数据集对随机森林模型进行训练,通过十折交叉验证评估模型性能。
-
流量检测:对待测网络流量进行数据包聚合和特征提取,然后使用训练好的模型进行分类预测。
四、实验验证
(一)数据集