互联网迅速发展,根据google的公布数据,目前索引的独立页面超过一万亿,并且这个数字还在不断的刷新.互联网成为人学习和娱乐的主要工具,目前每个人上网时间达到2小时以上,分析和监控用户的上网类型,称为一个新的趋势.
依据人工方式来分类显然不可能的,因为网站数量大,人工分类主观意识强,影响分类的准确性与真实性.因此有必要建立依据自然语言处理的和爬虫技术对海量的网站进行自动化分类,并保存分类结果.分类结果供其他场景使用.
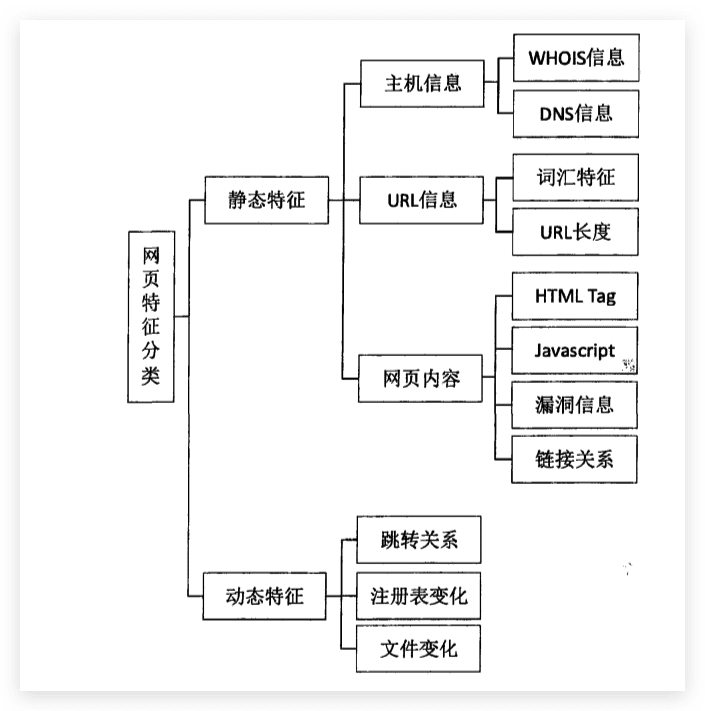
基于分类的数目又可以分成二元分类和多级分类。基于分配给每个例子的分类的数目, 又可分为单标签分类和多标签分类。如果是多级分类,比如一个四级分类,艺术,商业, 计算机和运动,它可以为单标签,同时也可以是多标签,即一个例子可以属于一个,两个 或所有的类别。
客户用防火墙想控制墙内用户访问哪些方面的网页进行监控管理,这就意味着要对存量的网站进行分类,方便客户对某一类站点进行阻断,比如,对色情网站进行阻断. 实现的思路:通过爬虫的方式对存量的网页进行信息获取,采用自然语言处理的技术,对爬取的url进行分类,并存储.将分类好的站点文件,预制到防火墙内部.
词向量构建
词语是语义的最小单位,如何构建词向量是语义分析和文本分类的关键.
算法方法