跳表使用空间换时间的设计思路,通过构建多级索引来提高查询的效率,实现了基于链表的“二分查找”。跳表是一种动态数据结构,支持快速的插入、删除、查找操作,时间复杂度都是 O(logn)。
跳表的空间复杂度是 O(n)。跳表的实现非常灵活,可以通过改变索引构建策略,有效平衡执行效率和内存消耗。跳表的代码比起红黑树来说,要简单、易读。
链表加多级索引的结构,就是跳表。
对于一个单链表,即便链表中存储的数据是有序的,如果要查找某个数据,也只能从头到尾遍历,时间复杂度是 O(n)。
1570442602270
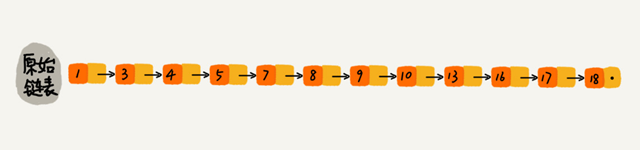
对链表建立一级“索引”,每两个结点提取一个结点到上一级,把抽出来的那一级叫作索引或索引层。图中的 down 表示 down 指针,指向下一级结点。
1570442615779
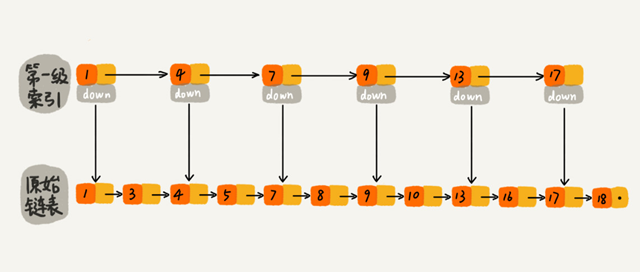
这样就可以先在索引层遍历,然后通过索引层结点的 down 指针,下降到原始链表这一层,继续遍历。
比如要查找16,当在索引层遍历到13时,发现索引层下一个节点是17大于目标16,则可从13的down指针下降到原始链表继续遍历。这样只需要再遍历 2 个结点,就可以找到值等于 16 的这个结点了。原来查找 16,需要遍历 10 个结点,加入一层索引后只需要遍历 7 个结点。
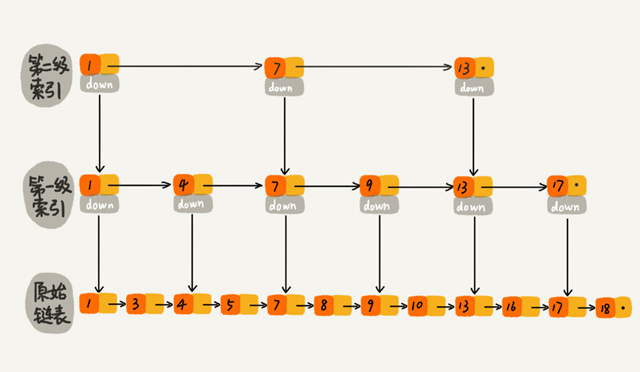
加来一层索引之后,查找一个结点需要遍历的结点个数减少了,查找效率提高了。继续再加一级索引,在第一级索引的基础之上,每两个结点就抽出一个结点到第二级索引。现在再查找 16,只需要遍历 6 个结点了,需要遍历的结点数量又减少了。
1570442649156
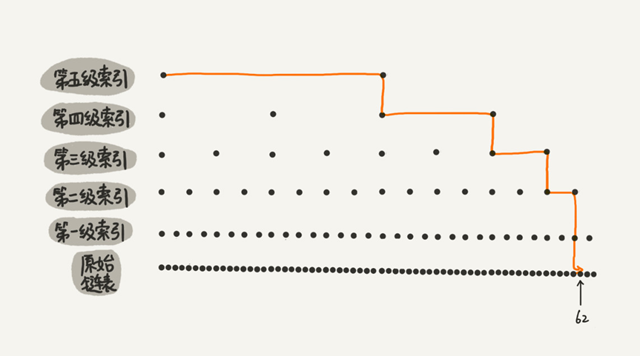
下图是一个包含 64 个结点的链表,建立五级索引。
1570442675055
在五级索引的作用下,查找 62 只需要遍历 11 个结点。当链表的长度 n 比较大时,比如 1000、10000 的时候,在构建多级索引之后,查找效率的提升就会非常明显。