大家好,我是AI拉呱,一个专注于人工智领域与网络安全方面的博主,现任资深算法研究员一职,热爱机器学习和深度学习算法应用,拥有丰富的AI项目经验,希望和你一起成长交流。关注AI拉呱一起学习更多AI知识。*
基于6个专用智能体、错误分类体系和真实数据库查询思维链推理,实现准确率达91%的框架落地实践
你向数据库发起查询:“显示上季度消费超过平均值的客户。”
AI生成SQL语句,执行后却返回错误。
重试一次,错误相同,只是表述略有差异。
第三次尝试,依然失败。
这种情况在文本转SQL(Text-to-SQL)系统中极为常见。即便像GPT-4这样的模型,在处理复杂连接、模糊列引用和聚合逻辑时也会出错。大多数系统只会盲目重试,在细微的表述差异中重复相同的错误。
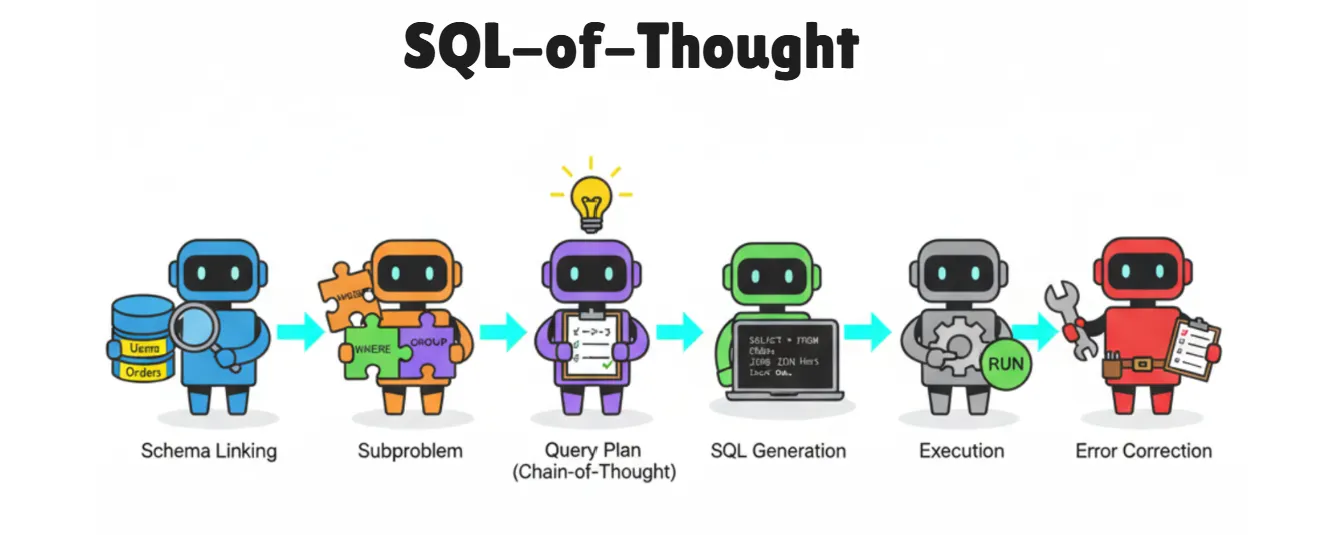
近期,马克斯·普朗克研究所与AWS生成式AI团队联合发表的一篇论文提出了“SQL-of-Thought”框架——这是一种多智能体系统,能将31种SQL错误分类,并通过系统化方式修正。该框架在Spider基准测试中准确率达到91.59%。
我没有止步于解读研究内容,而是搭建了一个可运行的演示系统,以验证该方案在真实错误场景下的表现。
以下是我的实践心得。
传统方案通过单次大型语言模型(LLM)调用,直接将自然语言转换为SQL。
当查询失败时,系统会重试,或许会调整提示词,然后再次尝试。
这种方式既无法系统性理解错误原因,也不能根据错误类型实施针对性修正。
常见的失败场景包括:
该论文的核心洞见在于:将错误划分为9大类下的31种具体类型,再根据错误分类实施针对性修正。
在深入演示系统前,先了解SQL-of-Thought的核心工作原理。