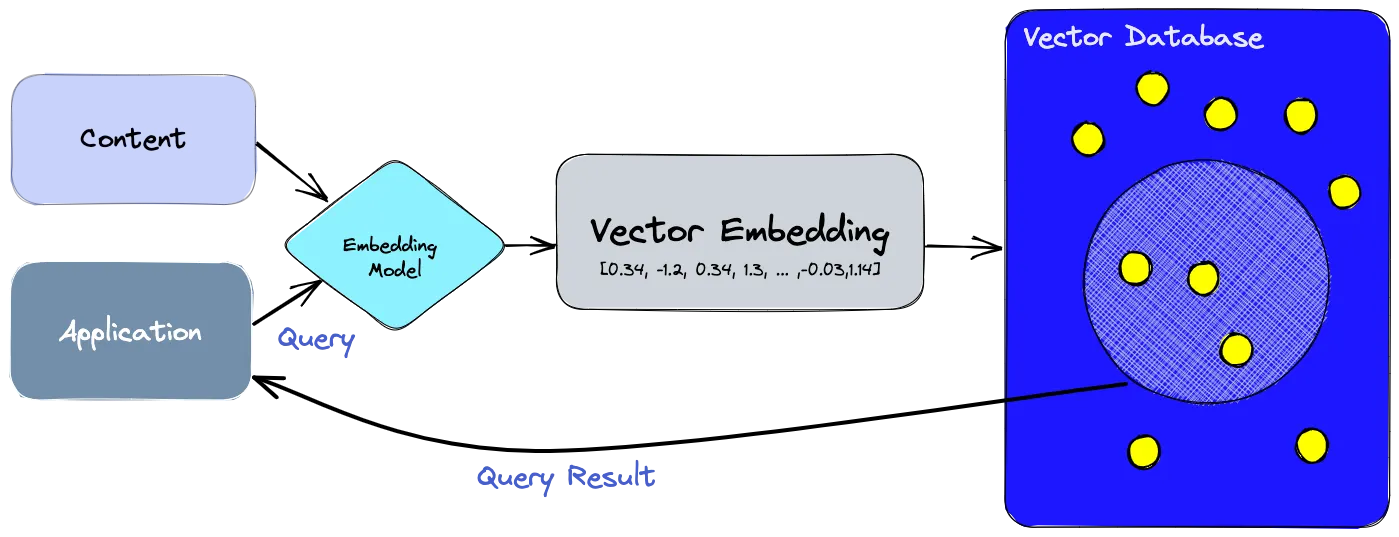
向量数据库存储数值化的“语义”(即嵌入向量),并支持通过相似度而非精确文本进行搜索。
在如今这个AI驱动的时代,语义搜索、向量嵌入、检索增强生成(RAG)等术语正逐渐成为日常技术词汇的一部分。我在X(原Twitter)上关注了大部分AI领域的技术人士,几乎每隔一天就能看到与向量数据库(Vector DB)相关的内容。
向量数据库是一款功能强大的后台支撑引擎,能让AI更智能、响应更迅速、对上下文的感知更敏锐。
本文将为你详细介绍向量数据库的定义、工作原理、重要性,以及它与传统数据库的区别。内容涵盖理论知识、工具对比、实际应用场景,还包含一个基于Sentence-Transformers和Qdrant(本地部署)的Python实战教程。
若你觉得本文对你有帮助,欢迎点赞支持,这能让更多人看到这篇文章。为了撰写本文,我投入了大量时间和精力,希望能帮助所有想要学习向量数据库的读者。你也可以点击下方链接阅读我的其他博客:
《适合你的AI作品集的10个LLM与RAG项目(2025-2026)》
检索增强生成(RAG)就像是为你的AI升级了内存,还配备了谷歌搜索栏。它不再根据训练时“认为”学到的内容编造答案,而是能获取实时、相关的信息——本质上,它不再“幻觉输出”,而是开始引用来源了。 techwithram.medium.com
在AI领域,向量是数据的数值化表示形式。无论是句子、图像,甚至是音频片段,都能被转化为一长串数字(维度通常在100到1000以上),这些数字捕捉了数据的语义或特征信息。
举个例子:
“巴黎是法国的首都。”
→ [0.13, 0.92, -0.34, …, 0.45] 这类数值化表示被称为嵌入向量(Embeddings),正是因为有了它们,大型语言模型(LLMs)才能更好地理解“巴黎”和“伦敦”之间的语义关联,而不仅仅是通过字符串对比来判断。
但传统数据库(如MySQL、MongoDB)并非为存储和搜索数百万个高维向量而设计。
这正是向量数据库的用武之地。
向量数据库是一款专门设计的系统,旨在高效存储、建立索引和搜索向量嵌入,尤其适用于大规模数据场景。
与传统数据库通过行或列进行匹配不同,向量数据库基于语义相似度返回结果。
具体来说: