我们当下所熟悉的互联网,本质是为人类打造的产物。网页的设计围绕“浏览器呈现效果”展开,配备了菜单、导航栏、图片等元素,以提升人类用户的视觉体验与操作便捷性。
然而,对于大语言模型(LLMs)这类AI系统而言,设计美观与否毫无意义。它们真正关注的是清晰的结构、简洁的文本,以及有价值的示例。而目前,互联网上的绝大多数内容,都难以被LLMs有效学习和利用。
这就引出了一个关键问题:
倘若我们能让网站(或任何知识来源)不仅“对人类友好”,同时也“对AI友好”,会产生怎样的改变?
这正是“LLM化(LLMification)”理念的核心——将知识资源转化为针对大语言模型优化的格式。这一理念的近期灵感,主要来自安德烈·卡帕西(Andrej Karpathy)与杰里米·霍华德(Jeremy Howard)两位专家的观点。
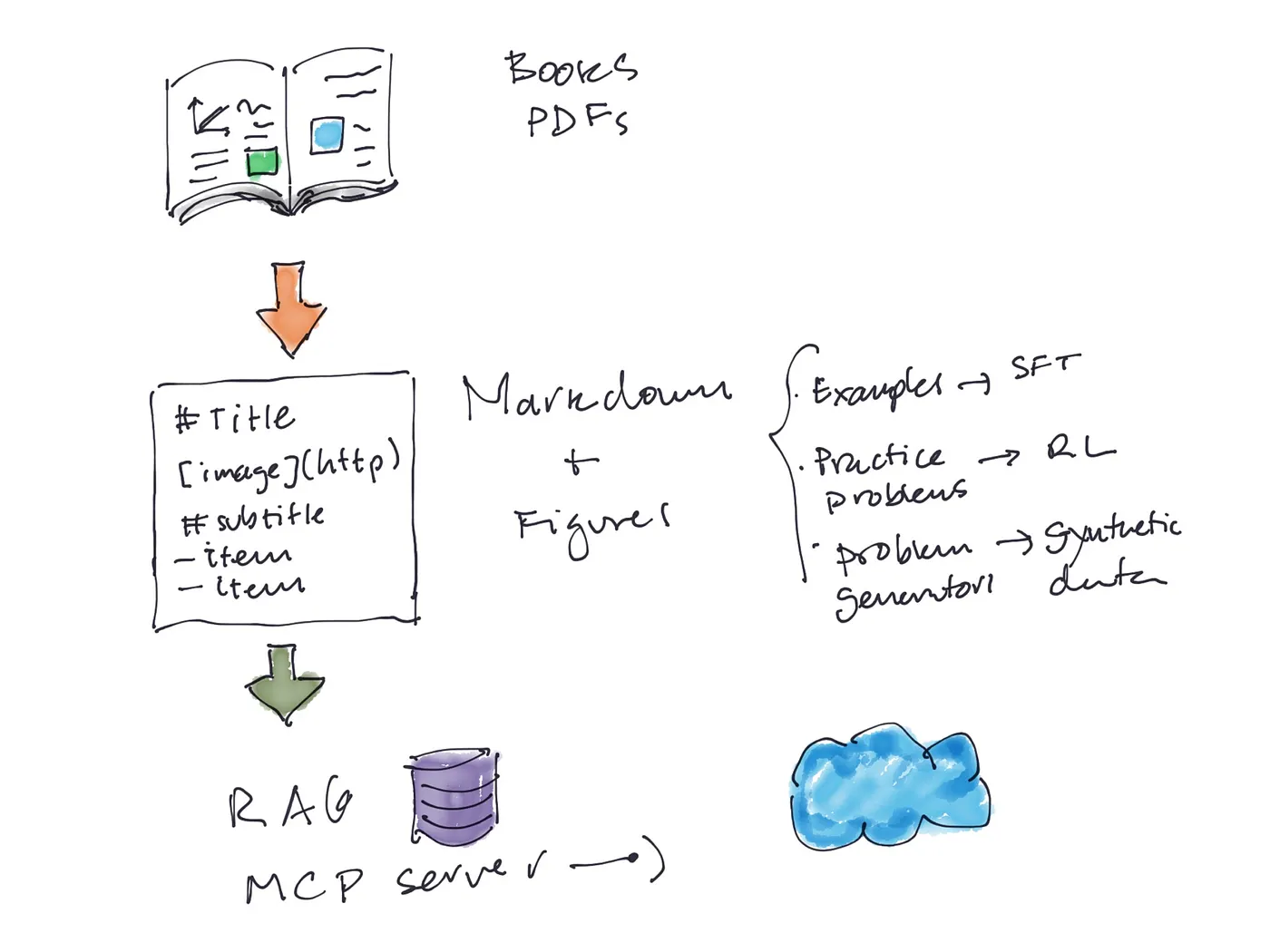
安德烈·卡帕西曾在一条推文中设想:每一本教科书都能实现完美的“LLM化”。无需让AI艰难地逐页读取PDF文件,我们完全可以为模型量身打造一套结构化的内容版本。
具体实现流程如下:
最终能实现什么效果?LLM可以像学生一样“学习物理课程”——阅读知识点解析、尝试示例练习、完成课后习题。这一思路不仅适用于教科书,还能推广到任何知识来源。
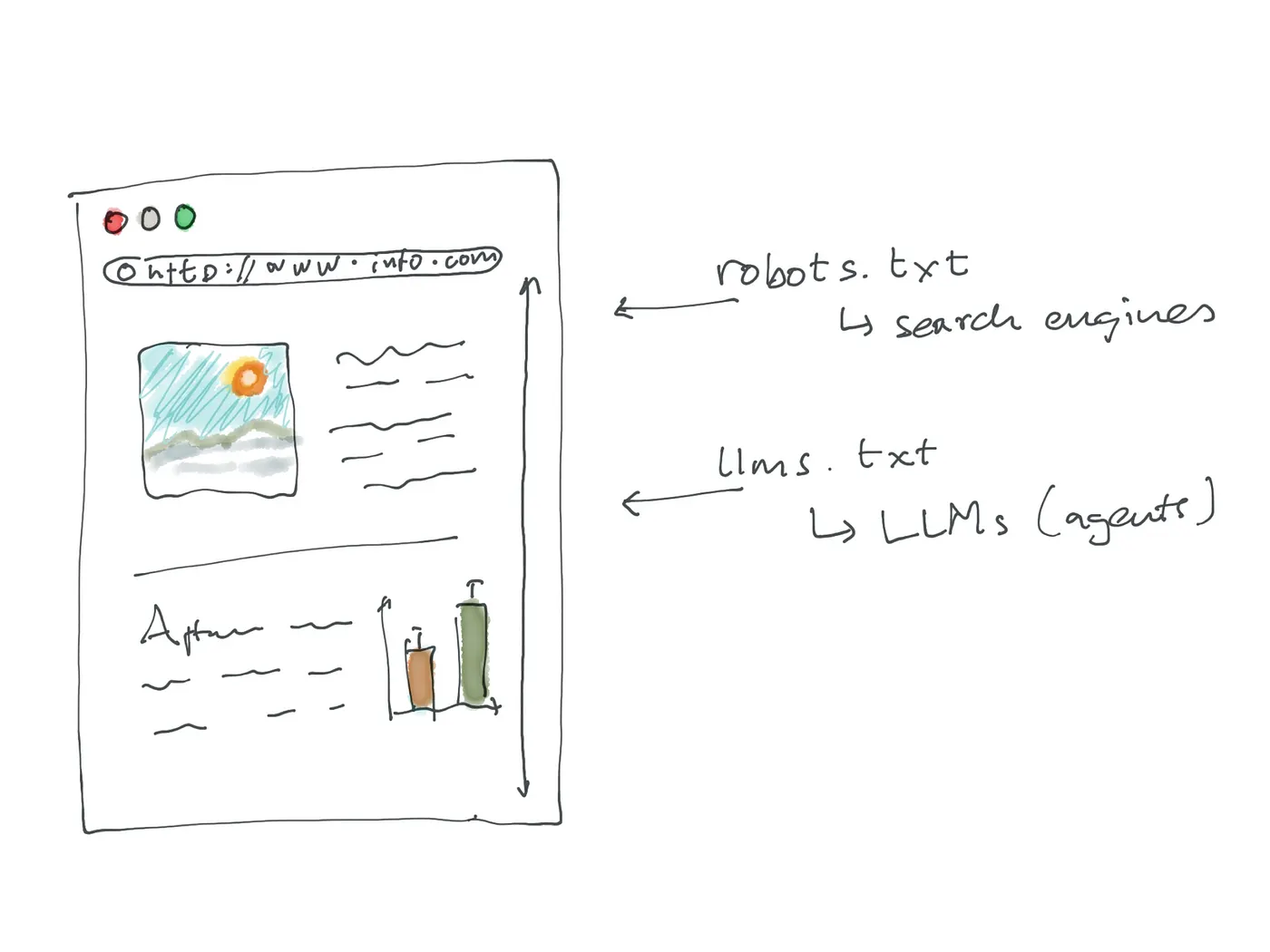
杰里米·霍华德近期提出的一个方案,也与“LLM化”理念异曲同工。他在关于“llms.txt”的提案中提出了一个问题:如何从源头让网站更易于被LLM抓取和索引?
在他的方案中,知识来源聚焦于“网站”,而针对LLM的内容转化无需大规模重构,只需遵循一个特定文本文件的标准即可——核心思路与卡帕西的设想高度契合。
就像“robots.txt”文件用于告知搜索引擎“哪些内容可索引”一样,“llms.txt”是一个放置在网站根目录下的简易Markdown文件,主要功能包括:
这种方式无需重新格式化网站所有内容,仅通过一个“轻量级信号”,就能为LLM指明获取有效信息的方向。
尽管卡帕西与霍华德的方案均以“提升内容对AI的友好性”为目标,但二者的侧重点存在明显差异: