散列表来源于数组,它借助散列函数对数组这种数据结构进行扩展,利用的是数组支持按照下标随机访问元素的特性。散列表两个核心问题是散列函数设计和散列冲突解决。散列冲突有两种常用的解决方法,开放寻址法和链表法。散列函数设计的好坏决定了散列冲突的概率,也就决定散列表的性能。
散列表的英文叫“Hash Table”,也叫它“哈希表”或者“Hash 表”,散列表用的是数组支持按照下标随机访问数据的特性,是数组的一种扩展。
散列表利用了数组按照下标随机访问的时候时间复杂度是 O(1) 的特性。通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当按照键值查询元素时,用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。
1570442938362
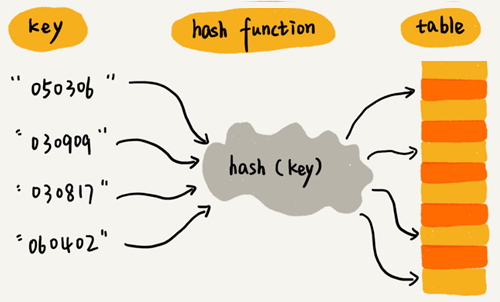
散列函数,可以定义成hash(key),其中 key 表示元素的键值,hash(key) 的值表示经过散列函数计算得到的散列值。
散列函数,顾名思义,它是一个函数。我们可以把它定义成hash(key),其中 key 表示元素的键值,hash(key) 的值表示经过散列函数计算得到的散列值。
散列函数设计的三点基本要求:
对于第一点,因为数组下标是从 0 开始的,所以散列函数生成的散列值也要是非负整数。
对于第二点,相同的 key,经过散列函数得到的散列值也应该是相同的。
对于第三点,几乎无法找到一个完美的无冲突的散列函数,即便像业界著名的MD5、SHA、CRC等哈希算法,也无法完全避免这种散列冲突。而且,因为数组的存储空间有限,也会加大散列冲突的概率。针对散列冲突问题,需要通过其他途径来解决。
常用的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)。
开放寻址法的核心思想是,如果出现了散列冲突,就重新探测一个空闲位置,将其插入。