$ python3 pack.py cover.png file.zip output.png
import zlib
from struct import unpack_from
import sys
PNG_MAGIC = b"\\x89PNG\\r\\n\\x1a\\n"
if len(sys.argv) != 4:
print(f"USAGE: {sys.argv[0]} cover.png content.bin output.png")
exit()
# this function is gross
def fixup_zip(data, start_offset):
# find the "end of central directory" marker
end_central_dir_offset = data.rindex(b"PK\\x05\\x06")
# find the number of central directory entries
cdent_count = unpack_from("<H", data, end_central_dir_offset+10)[0]
# find the offset of the central directory entries, and fix it
cd_range = slice(end_central_dir_offset+16, end_central_dir_offset+16+4)
central_dir_start_offset = int.from_bytes(data[cd_range], "little")
data[cd_range] = (central_dir_start_offset + start_offset).to_bytes(4, "little")
# iterate over the central directory entries
for _ in range(cdent_count):
central_dir_start_offset = data.index(b"PK\\x01\\x02", central_dir_start_offset)
# fix the offset that points to the local file header
off_range = slice(central_dir_start_offset+42, central_dir_start_offset+42+4)
off = int.from_bytes(data[off_range], "little")
data[off_range] = (off + start_offset).to_bytes(4, "little")
central_dir_start_offset += 1
png_in = open(sys.argv[1], "rb")
content_in = open(sys.argv[2], "rb")
png_out = open(sys.argv[3], "wb")
# check the PNG magic is present in the input file, and write it to the output file
png_header = png_in.read(len(PNG_MAGIC))
assert(png_header == PNG_MAGIC)
png_out.write(png_header)
idat_body = b""
# iterate through the chunks of the PNG file
while True:
# parse a chunk
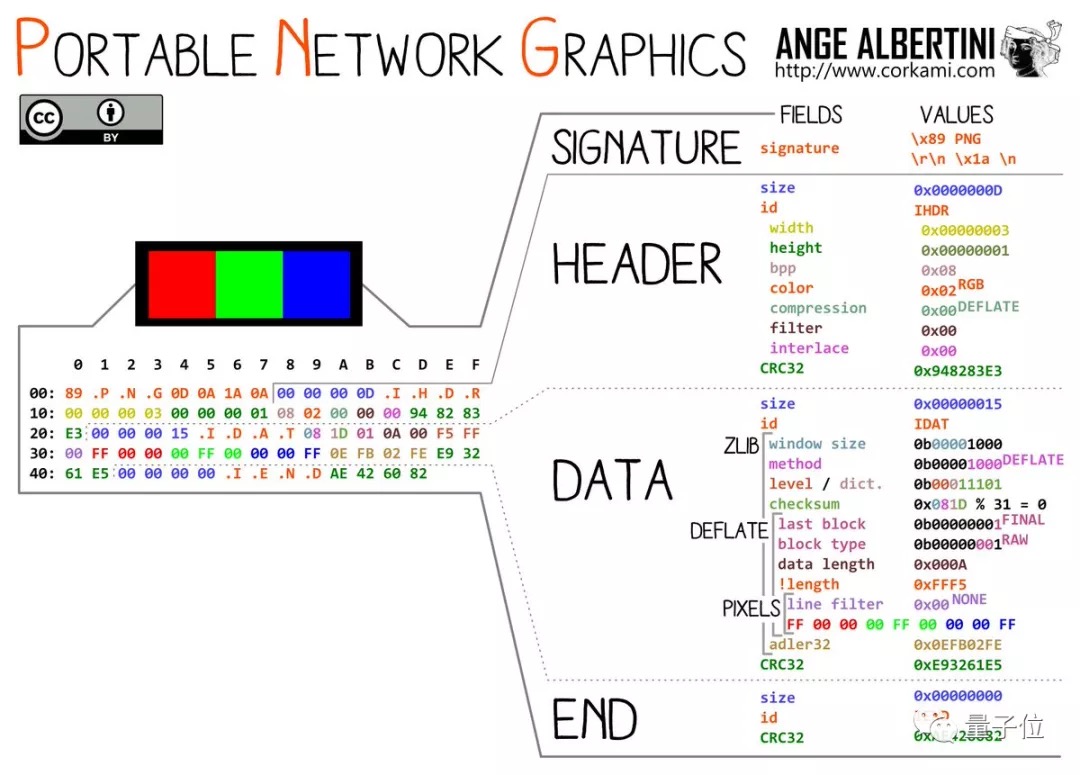
chunk_len = int.from_bytes(png_in.read(4), "big")
chunk_type = png_in.read(4)
chunk_body = png_in.read(chunk_len)
chunk_csum = int.from_bytes(png_in.read(4), "big")
# if it's a non-essential chunk, skip over it
if chunk_type not in [b"IHDR", b"PLTE", b"IDAT", b"IEND"]:
print("Warning: dropping non-essential or unknown chunk:", chunk_type.decode())
continue
# take note of the image width and height, for future calculations
if chunk_type == b"IHDR":
width, height = unpack_from(">II", chunk_body)
print(f"Image size: {width}x{height}px")
# There might be multiple IDAT chunks, we will concatenate their contents
# and write them into a single chunk later
if chunk_type == b"IDAT":
idat_body += chunk_body
continue
# the IEND chunk should be at the end, now is the time to write our IDAT
# chunk, before we actually write the IEND chunk
if chunk_type == b"IEND":
start_offset = png_out.tell()+8+len(idat_body)
print("Embedded file starts at offset", hex(start_offset))
# concatenate our content that we want to embed
idat_body += content_in.read()
if len(idat_body) > width * height:
exit("ERROR: Input files too big for cover image resolution.")
# if its a zip file, fix the offsets
if sys.argv[2].endswith(".zip"):
print("Fixing up zip offsets...")
idat_body = bytearray(idat_body)
fixup_zip(idat_body, start_offset)
# write the IDAT chunk
png_out.write(len(idat_body).to_bytes(4, "big"))
png_out.write(b"IDAT")
png_out.write(idat_body)
png_out.write(zlib.crc32(b"IDAT" + idat_body).to_bytes(4, "big"))
# if we reached here, we're writing the IHDR, PLTE or IEND chunk
png_out.write(chunk_len.to_bytes(4, "big"))
png_out.write(chunk_type)
png_out.write(chunk_body)
png_out.write(chunk_csum.to_bytes(4, "big"))
if chunk_type == b"IEND":
# we're done!
break
# close our file handles
png_in.close()
content_in.close()
png_out.close()
项目地址: https://github.com/DavidBuchanan314/tweetable-polyglot-png